Distributed GPT model (part 3): Megatron-LM tensor parallelism
This post follows from the previous posts Distributed training of a GPT model using DeepSpeed and Distributed training of a GPT model using DeepSpeed (pipeline parallelism), where we implemented Data and Pipeline parallelism on a GPT model. Data and pipeline parallelism are 2 dimensions of the 3D parallelism of ML models, via Data, Pipeline and Tensor/Model parallelism. In this post, we will discuss tensor (model) parallelism, particularly the Megatron-LM implementation.
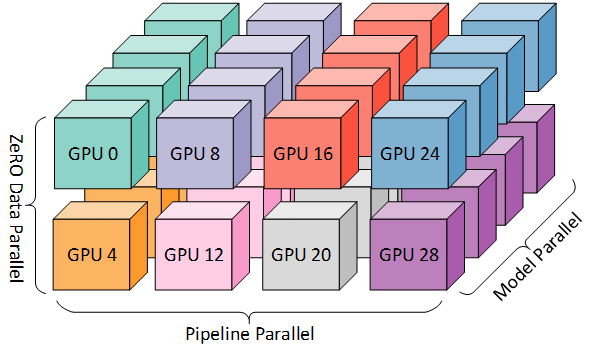
The 3D parallelism aims at partitioning (color-coded) compute resources across the 3D space of data, pipeline and tensor (model) dimensions. In this post we will focus on model/tensor parallelism. Source: Microsoft Research Blog
Tensor parallelism, vertical parallelism, intra-layer parallelism, activation parallelism or (most commonly and confusingly) model parallelism, is the third dimension of parallelism and aims at partitioning computation across the model’s tensor dimensions (e.g., sharding linear layer weights and corresponding activations). This is a hard problem: in practice we must decide the dimension of tensor partitioning (row-wise, column-wise, or none) and adapt the communication and computation accordingly. Therefore, it is a model- and data-specific implementation.

A representation of tensor parallelism on a fully-connected DNN, on two processors \(p0\) and \(p1\). Input sample and activations are distributed across different processors. Red lines represent the activations that have to be communicated to a different processor.
Looking at the previous picture, we notice a major drawback in this method. During training, processors need to continuously communicate activations that are needed across the processor network. This communication is synchronous and can limit overlap with compute (depending on the implementation). And it creates a major drawback on the execution as it can require a tremendous amount of communication at every layer of the network and for every input batch.
There are several alternative ways to distribute multi-dimensional tensors across several compute nodes, that aim at reducing the number of communication steps or the amount of communication volume. In this post, we will detail and implement the Megatron-LM approach.
Megatron-LM tensor parallelism
We can have a better understanding if we try to replicate the partitioning suggested by Megatron-LM in the paper Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. The main rationale in Megatron-LM is that Transformer-based models have two main components - a feed-forward (MLP) and an attention block - and we can do a forward and a backward pass on each of these blocks with a single collective communication step.

The MLP and self-attention blocks in the Megatron-LM implementation. \(f\) and \(g\) are conjugate identity and all-reduce operations: \(f\) is an identity operator in the forward pass and all-reduce in the backward pass while \(g\) is an all-reduce in the forward pass and identity in the backward pass. Source: Megatron-LM paper
The rationale is the following: the MLP is sequence of (1) a MatMul \(AX\), (2) a GeLU \(Y\); a (3) MatMul \(YB\) and a (4) dropout layer. Let’s focus on the first two operations:
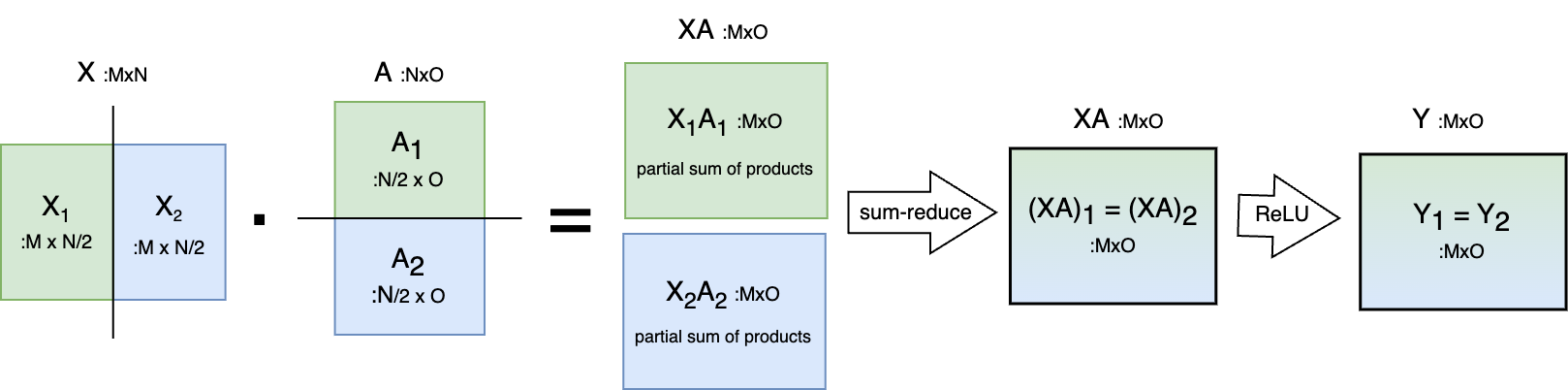
- “One option to parallelize the GEMM is to split the weight matrix \(A\) along its rows and input \(X\) along its columns. […] This partitioning will result in \(Y = GeLU(X_1 A_1 + X_2 A_2)\). Since GeLU is a nonlinear function, \(GeLU (X_1 A_1 + X_2 A_2) \neq GeLU( X_1 A_1 ) + GeLU (X_2 A_2)\) and this approach will require a synchronization point (sum-reduce) before the GeLU function”. We can follow this approach - pictured below - for each of the 2 MatMuls, yielding a total of two communication steps.
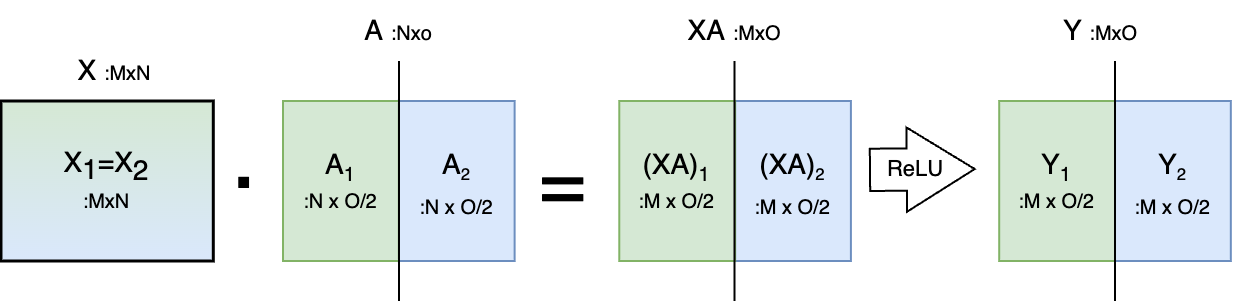
- Another option is to not split \(X\) and split \(A\) along its columns, which “allows the GeLU nonlinearity to be independently applied to the output of each partitioned GEMM”. The output of the GeLU \(Y\) is then \([Y_1, Y_2] = [GeLU (X A_1), GeLU(X A_2)]\) and this removes a synchronization point. After the MatMul and GeLU is done, we must follow with another MatMul and a dropout. Note that if we follow this approach (pictured below), the output \(Y\) of the first MatMul (which is the input for the second MatMul) is split column-wise. Therefore, Megatron will then use the previous approach for the second MatMul, which requires 1 collective communication step. We therefore perform 1 communication step for 2 MatMuls.
The algorithm of the attention mechanism is analogous, except that instead of a single MatMul \(AX\) at the beginning of the workflow, we perform three MatMuls \(XV\), \(XQ\) and \(XK\) for the value, query and key matrices of the attention mechanism. Therefore, this algorithm requires one (not two) communication step per MLP and attention block.
Megatron-LM makes this implementation very simple, by adding only the \(f\) and \(g\) functions to the serial use case. Following the paper: “\(f\) is an identity operator in the forward pass and all reduce in the backward pass while \(g\) is an all reduce in the forward pass and identity in the backward pass”. So we can implement this as:
class Megatron_f(torch.autograd.Function):
""" The f function in Figure 3 in Megatron paper """
@staticmethod
def forward(ctx, x, mp_comm_group=None):
ctx.mp_comm_group = mp_comm_group
return x
@staticmethod
def backward(ctx, gradient):
dist.all_reduce(gradient, dist.ReduceOp.SUM, group=ctx.mp_comm_group)
return gradient, None
and
class Megatron_g(torch.autograd.Function):
""" The g function in Figure 3 in Megatron paper """
@staticmethod
def forward(ctx, x, mp_comm_group=None):
dist.all_reduce(x, dist.ReduceOp.SUM, group=mp_comm_group)
return x
@staticmethod
def backward(ctx, gradient):
return gradient, None
Note that we added an extra argument mp_comm_group that refers to the model-parallel communication group. This refers to the communication group to allow us to combine MP with other types of parallelism. As an example, if you have 8 GPUs, you can have 2 data parallel groups of 4 model parallel GPUs. We now add tensor parallelism to the MLP by inserting \(f\) and \(g\) in the forward pass, at the beginning and end of the block, just like in the paper:
class Megatron_FeedForward(nn.Module):
""" the feed forward network (FFN) in the paper, with tensor parallelism as in Megatron-LM MLP block"""
def __init__(self, n_embd, mp_comm_group=None):
super().__init__()
self.mp_comm_group = mp_comm_group
#Fig 3a. MLP: splits first GEMM across columns and second GEMM across rows
n_embd_mid = n_embd * 4
if self.mp_comm_group:
n_embd_mid //= dist.get_world_size(group=self.mp_comm_group)
self.fc1 = nn.Linear(n_embd, n_embd_mid)
self.fc2 = nn.Linear(n_embd_mid, n_embd, bias=False) # <-- no bias here
self.fc2_bias = nn.Parameter(torch.zeros(n_embd)) # <-- bias added after all-reduce
self.dropout = nn.Dropout(dropout)
def forward(self, x):
if self.mp_comm_group:
x = Megatron_f.apply(x, self.mp_comm_group)
y = F.gelu(self.fc1(x))
z = self.fc2(y) # matmul only (partial)
if self.mp_comm_group:
z = Megatron_g.apply(z, self.mp_comm_group)
z = z + self.fc2_bias # <-- bias AFTER all-reduce
z = self.dropout(z)
return z
Note that the sum-reduce is added after the matmul but before the bias of the second linear layer, for correctness. The attention block follows a similar approach, however:
- Q/K/V projections are column-parallel: we split the output features (i.e., split the number of heads / hidden width), so each rank owns a subset of heads.
- The attention softmax is computed locally per rank (because each rank’s heads are independent).
- The output projection is row-parallel, and that’s where you typically do the all-reduce (to combine partial output contributions).
The multi-head attention block and FFN can then be written as:
class Megatron_MHA(nn.Module):
"""
Megatron-LM tensor-parallel Multi-Head Self-Attention (Fig. 3b style):
- Q/K/V GEMM is column-parallel: each rank owns a subset of heads (local heads).
Use Megatron_f on the input (identity forward, all-reduce backward) to match
column-parallel input-gradient behavior.
- Attention (softmax path) is fully local per rank (no communication).
- Output projection is row-parallel: each rank projects its local concat heads
to n_embd, then Megatron_g all-reduces the output (sum) across ranks.
"""
def __init__(self, n_embd, n_head, block_size, dropout, mp_comm_group=None):
super().__init__()
self.mp_comm_group = mp_comm_group
self.n_embd = n_embd
self.n_head = n_head
self.tp_size = dist.get_world_size(group=mp_comm_group) if mp_comm_group else 1
if n_head % self.tp_size != 0:
raise ValueError(f"n_head ({n_head}) must be divisible by tp_size ({self.tp_size}).")
self.n_head_local = n_head // self.tp_size
if n_embd % n_head != 0:
raise ValueError(f"n_embd ({n_embd}) must be divisible by n_head ({n_head}).")
self.head_dim = n_embd // n_head
self.hidden_local = self.n_head_local * self.head_dim
# Column-parallel QKV: each rank produces Q,K,V only for its local heads.
self.qkv = nn.Linear(n_embd, 3 * self.hidden_local, bias=False)
# Row-parallel output projection: consumes local heads and produces full n_embd,
# then we all-reduce (Megatron_g) to combine ranks.
self.proj = nn.Linear(self.hidden_local, n_embd, bias=False)
self.register_buffer("tril", torch.tril(torch.ones(block_size, block_size)))
self.attn_dropout = nn.Dropout(dropout)
self.out_dropout = nn.Dropout(dropout)
def forward(self, x):
B, T, C = x.shape
if C != self.n_embd:
raise ValueError(f"Expected x.shape[-1] == {self.n_embd}, got {C}.")
# Column-parallel input handling: identity forward, all-reduce on backward.
if self.mp_comm_group:
x = Megatron_f.apply(x, self.mp_comm_group)
# Local QKV for local heads
qkv = self.qkv(x) # (B, T, 3*hidden_local)
q, k, v = qkv.split(self.hidden_local, dim=-1)
# (B, T, hidden_local) -> (B, n_head_local, T, head_dim)
q = q.view(B, T, self.n_head_local, self.head_dim).transpose(1, 2)
k = k.view(B, T, self.n_head_local, self.head_dim).transpose(1, 2)
v = v.view(B, T, self.n_head_local, self.head_dim).transpose(1, 2)
# Attention scores: (B, n_head_local, T, T) -- LOCAL, no comm
wei = (q @ k.transpose(-2, -1)) * (self.head_dim ** -0.5)
# Causal mask (broadcasts over B and n_head_local)
wei = wei.masked_fill(self.tril[:T, :T] == 0, float("-inf"))
wei = F.softmax(wei, dim=-1)
wei = self.attn_dropout(wei)
# Context: (B, n_head_local, T, head_dim)
out = wei @ v
# Concat heads: (B, T, hidden_local)
out = out.transpose(1, 2).contiguous().view(B, T, self.hidden_local)
# Row-parallel output projection: local matmul then all-reduce sum on forward
out = self.proj(out) # (B, T, n_embd) partial contribution
if self.mp_comm_group:
out = Megatron_g.apply(out, self.mp_comm_group)
out = self.out_dropout(out)
return out
Sharding activations to reduce memory (all-reduce = reduce-scatter + all-gather)
The main caveat of this method is that the input X is replicated across all GPUs. This is not ideal, as large inputs may require a large memory chunk and may not fit in one GPU. This is particularly relevant during training, where activations during the forward pass need to be stored for the backward pass. To reduce the memory consumption, one can only hold a shard/subset of the input data and activations on each GPU. To do this, we simply replace the all-reduce by a reduce-scatter (so that the output of the all-reduce is sharded across GPUs), and add an additional all-gather at the beginning of the execution (that will gather all shards of X onto the full X, as required by the first matmul). As activations, we only need to keep the shard of X produced between the reduce-scatter of the current block and the all-gather of the next. With this, we increase the number of collective communication steps from 1 to 2, but reduce the activation memory linearly by the number of GPUs.
Detour: tensor parallelism on Convolutional Neural Nets
The whole point of Megatron-LM was to reduce the amount of high-volume communication steps due to the high volume of data involved per step. However, it is relevant to mention that tensor parallelism has some use cases where it can be efficient and low-volume communication. An example is the parallelism of Convolutional Neural Networks. In practice, due to the kernel operator in CNNs (which has a short spatial span), the amount of activations to be communicated is limited to the ones that neighboring activations need. This method has been detailed by Dryden et al. (Improving Strong-Scaling of CNN Training by Exploiting Finer-Grained Parallelism, Proc. IPDPS 2019). The functioning is illustrated in the picture below and is as follows:
- Input data and activations are split across the height and width dimensions among processors;
- For a given convolutional layer, the convolution can be computed independently by each processor, with the exception of the activations at the split boundaries. These activations (the halo region in purple in the picture below) will need to be communicated at every forward/backward step.
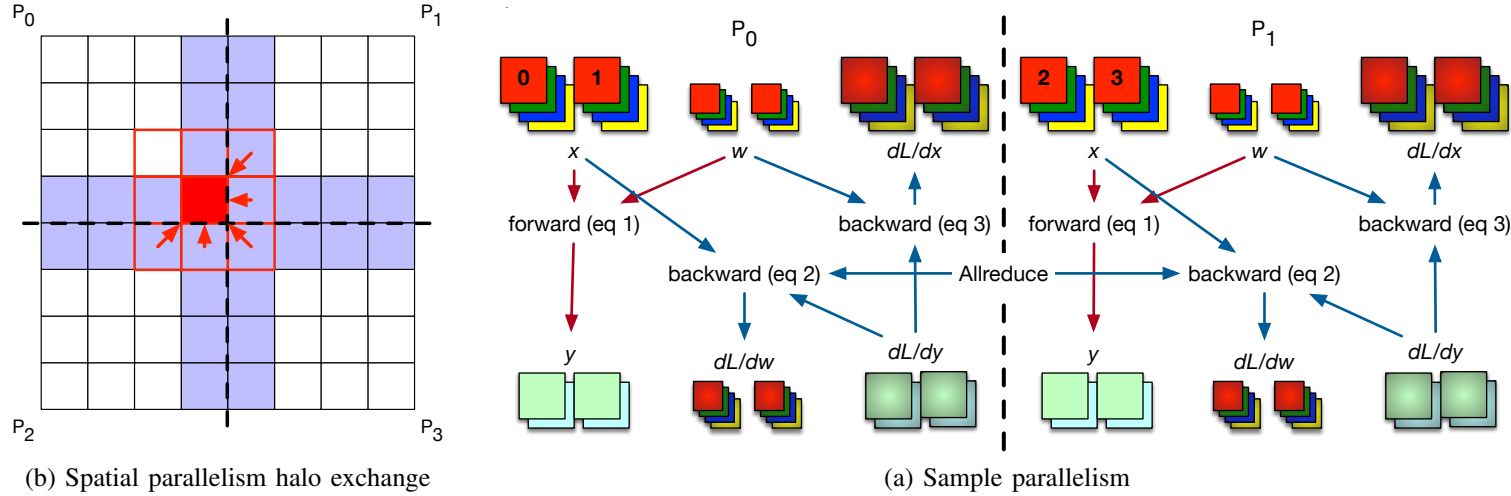
Illustration of tensor parallelism applied to a Convolutional Neural network. LEFT: splitting of activations on a 2D input across four processors \(p0-p3\). red box: center of the 3x3 convolution filter; red arrow: data movement required for updating neuron in center of filter; violet region: halo region formed of the elements that need to be communicated at every step. RIGHT: communication between processors \(p0\) and \(p1\). Red arrow: forward pass dependencies; blue arrow: backward pass dependencies;
Final remarks and code
There is ongoing work from PyTorch to support general model parallelism, where the user can pick row-wise split, column-wise split and sharding of individual tensors. Also, combining data, pipeline and tensor parallelism requires one to define the correct strategy for custom model parallelism.
As an important remark: finding the best parallelism strategy is hard, due to the high number of hyper-parameters: ZeRO stages, offloading, activation checkpointing intervals, pipeline parallelism stages, data parallelism, tensor parallelism, etc, as it depends on the ML model, data and hardware. In practice, our config file and parallelism settings are a manually-optimized ballpark figure of the default config file with some parameter grid search. In this topic, there is still plenty of work to be done to make it optimal, possibly by exploring the autotuning tools in DeepSpeed.
We just scratched the surface of DeepSpeed capabilities. There are plenty of resources that should also be explored. To name a few: autotuning (README.md) for parallelism hyper-parameters discovery; flops profiler measures the time, flops and parameters of individual layers, sparse attention kernels (API) to support long sequences of model inputs, such as text, image, or sound; communication optimizers offer the same convergence as Adam/LAMB but incur 26x less communication and 6.6x higher throughput on large BERT pretraining, monitor to log live training metrics to TensorBoard, csv file or other backend; model compression (API) via layer reduction, weight quantization, activation quantization, sparse pruning, row pruning, head pruning and channel pruning, to deliver faster speed and smaller model size.
Finally, the Megatron-LM tensor parallelism code has been added to the GPTlite-distributed repo, if you want to try it.