Distributed GPT model (part 4): context and sequence parallelism with Ulysses and Ring attention
We always thought about ML parallelism as a tridimensional problem, composed of data parallelism (with or without sharding), pipeline parallelism, and model/tensor parallelism. In practice, if take an input of shape (B, E), where B is the batch size and E is the size of the embeddings (channels, features), and we want to split that dataset across P processes, then:
- data parallelism splits the data dimension across processors, effectively leading to local (per-process) storage requirement of size
(B/P, E); - pipeline parallelism requires the same
(B/P, E)input per processor, but processes each mini-batch as a pipeline of iterative micro-batches with gradient accumulation, leading to a memory requirement of(B/P/Q, E)per iteration, whereQis micro-batch size; - model parallelism splits the embeddings/features across processors, requiring a local storage of shape
(B, E/P).
However, many model inputs and activations include an extra dimension that represents an (un)ordered sequence of tokens. Few examples are temporal datasets with a shape (B, T, E), and attention mechanisms with an attention matrix of shape (B, T, T). In these scenarios, we can explore parallelism on the sequence/time dimension T. Following the same notation as above, sequence parallelism requires a local storage of (B, T/P, E) per process. With that in mind, in this post, we will implement two existing techniques for sequence parallelism: Ulysses and Ring Attention. Our use case will be a model composed of a sequence of GPT-lite blocks, where each block is multi-head attention (MHA) module followed by a feed-forward network (FFN), with some normalization and skip connections.
Context Parallelism
Context parallelism is a parallelism scheme over the sequence dimension, and is best described in this NVIDIA post as:
Context Parallelism (“CP”) is a parallelization scheme on the dimension of sequence length. Unlike prior SP (sequence parallelism) which only splits the sequence of Dropout and LayerNorm activations, CP partitions the network inputs and all activations along sequence dimension. With CP, all modules except attention (e.g., Linear, LayerNorm, etc.) can work as usual without any changes, because they do not have inter-token operations.
In practice, parallelism on the sequence dimension works out-of-the-box on most layers for any input shaped (B, T/P, E). To implement Context Parallelism, all you only need is to a DataLoader and DistributedSampler that allocate chunks of sequences (instead of full sequences) to the data loading worker.
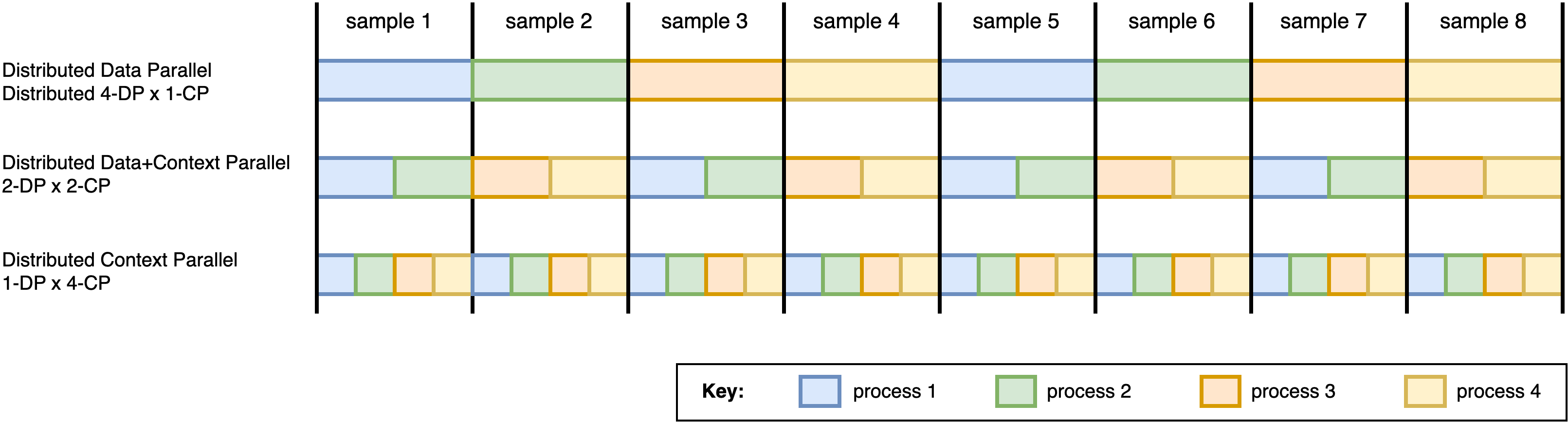
An example of data parallelism (DP) and context parallelism (CP) on 4 processes/GPUs (color-coded) and a dataset of 8 samples. First row: all 4 processes run on a distributed data parallelism execution. 2nd row: creating a custom DistributedSampler that yields chunks of sequences allows for a hybrid data- and context- parallelism execution of 2 groups of 2 context-parallel processes. Third row: no data-parallelism, all 4 processes execute context-parallelism of the same sample.
During training, the model runtime scales perfectly with the context parallelism degree. However, when it comes to the attention layer:
As for attention, the Q (query) of each token needs to compute with the KV (key and value) of all tokens in the same sequence. Hence, CP requires additional all-gather across GPUs to collect the full sequence of KV. Correspondingly, reduce-scatter should be applied to the activation gradients of KV in backward propagation. To reduce activation memory footprint, each GPU only stores the KV of a sequence chunk in forward and gathers KV again in backward.
In practice, to compute the attention module, one process needs its subset/chunk of queries, but needs the keys and values of the full sentence. The rationale is the following: take the attention head computation \(softmax \left(QK^T \right)V\), where all tensors are shaped B, T, E. If each process holds a subset of rows in \(Q\) as \(Q_p\) with shape B, T/P, E, then the dot-product \(Q_p K^T\) will have shape B, T/P, T. Because we are holding a full row of the dot-product, we can apply the \(softmax\) without any changes and get an attention matrix also of shape B, T/P, T. When multiplied by \(V\), this results in the attention output for that process shape B, T/P, E.
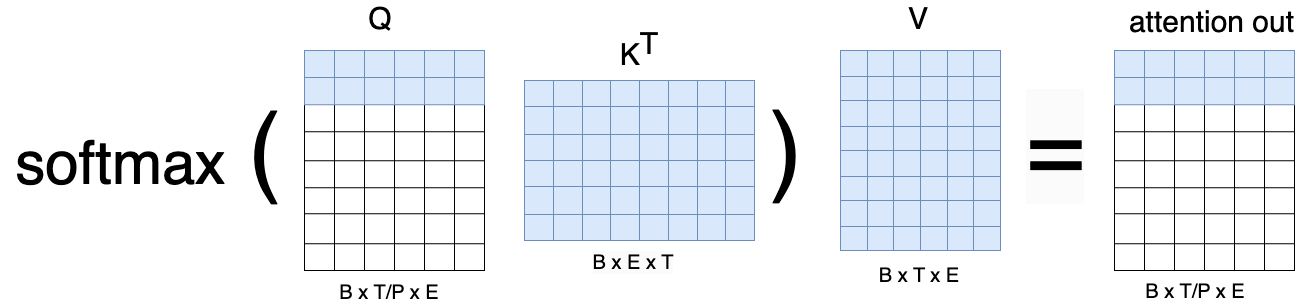
Requiring the full key and value tensors has two main drawbacks: an additional all_gather step to collect the full K and V, and the memory overhead to store those two tensors in full form. This is not ideal, therefore, in the following methods, we will look into how to parallelise the attention layer as well.
Ulysses sentence parallelism
Take the previous notation and assume a mini-batch split across the time dimension, with a local storage of (B, T/P, E) per process.
If we pass such shape to a feed-forward network, we achieve a parallelism or order P , as the T dimension will be treated as batch by the linear layers. However, in the case of the multi-head attention, there is the need for process communication as the time dependency across the tokens require inter-token communication to compute the full attention matrix of shape (H, B, T, T) for H attention heads and for a query, token and values tensor of local shape (B, T/P, E) . The (DeepSpeed) Ulysses parallelism approaches solves this by swapping the distributed view from time-split to head-split before and after the MHA attention module, as the following illustration:
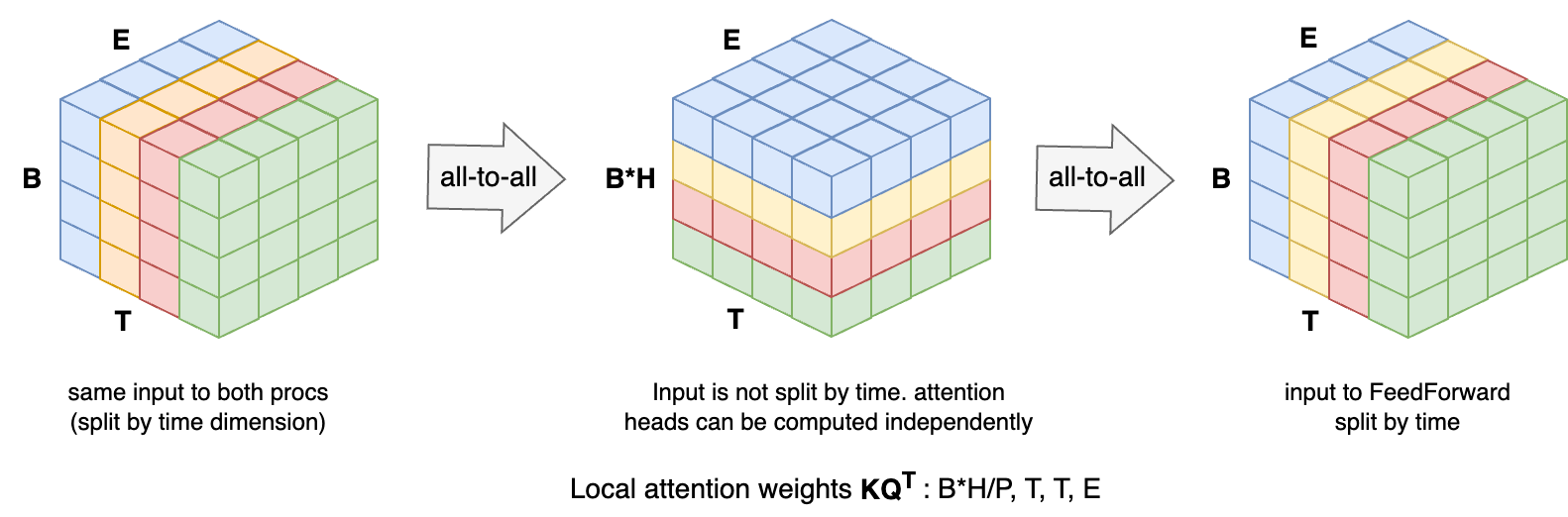
Overtiew of Ulysses sequence parallelism. Left: the initial view of the input tensor, distributed across 4 (color-coded) gpus, split by the time (T) dimension. Center: the first all-to-all changes the distributed tensor view from time- to head-split. Each process holds now complete sententes (ie not time-split) and can compute attention on the heads assigned to it, independently. Right: the second all-to-all reverts the view from head- to time-split.
In practice, the implementation of Ulysses only requires the extra steps that swap the distributed view of the input tensor from e.g. (H, B, T/P, E) to (H/P, B, T, E) and vice-versa. We can then implement the function dist_view_swap() that, given a tensor whose sentence is distributed across the process group group, swaps the distributed view by changing the split dimension from old_split_dim to new_split_dim as:.
def dist_view_swap(tensor: torch.Tensor, old_split_dim: int, new_split_dim: int, group: dist.ProcessGroup):
"""swaps the distributed split dimension of a tensor of glocal shape (H, B, T, E) across P processes"""
full_shape, P = list(tensor.shape), group.size()
full_shape[old_split_dim]*=P # full distributed shape
H, B, T, E = full_shape
send = torch.cat([tensor.chunk(P, dim=new_split_dim)[r].contiguous() for r in range(P)])
recv = torch.zeros_like(send)
dist.all_to_all_single(output=recv, input=send, group=group)
recv = torch.cat([recv.chunk(P)[r].view(H // P, B, T // P, E) for r in range(P)], dim=old_split_dim)
return recv
From here, the implementation is straightforward. The first (leftmost) all-to-all in the Ulysses diagram above only needs to convert the distributed view from time-split to head-split, while the backward pass needs to do the converse view swap:
class first_alltoall(torch.autograd.Function):
def forward(ctx, x, group=None):
ctx.group = group # save for backward pass
return dist_view_swap(x, old_split_dim=2, new_split_dim=0, group=ctx.group)
def backward(ctx, dout):
dout = dist_view_swap(dout, old_split_dim=0, new_split_dim=2, group=ctx.group)
return dout, None
The second all-to-all is analogous, except that it performs the opposite view changes in the forward and backward passes. Now we can implement the MultiHeadAttention module by calling both all-to-alls as modules:
from flash_attn.flash_attn_interface import flash_attn_func
class MultiHeadAttention(nn.Module):
def __init__(self, n_embd=256, d_head=128, n_heads=8, dropout_p=0.1, group=None):
""" An Ulysses multi-head attention. Variable names follow GPT-lite's post """
super().__init__()
self.d_head = d_head
self.n_heads = n_heads
self.keys = nn.ModuleList([nn.Linear(n_embd, d_head, bias=False) for _ in range(n_heads)])
self.queries = nn.ModuleList([nn.Linear(n_embd, d_head, bias=False) for _ in range(n_heads)])
self.values = nn.ModuleList([nn.Linear(n_embd, d_head, bias=False) for _ in range(n_heads)])
self.proj = nn.Linear(n_heads * d_head, n_embd)
self.dropout = nn.Dropout(dropout_p)
self.group = group # Ulysses group
if self.group is None:
self.group = dist.new_group(range(dist.get_world_size()))
def forward(self, x):
P, B, T, = self.group.size(), x.shape[0], x.shape[1] * self.group.size()
# Q, K and V embeddings: (B, T/P, E) -> (H, B, T/P, E)
q = torch.stack([q(x) for q in self.queries], dim=0)
k = torch.stack([k(x) for k in self.keys], dim=0)
v = torch.stack([v(x) for v in self.values], dim=0)
if P>1: # (H, B, T/P, E) -> (H/P, B, T, E)
q = first_alltoall.apply(q, self.group)
k = first_alltoall.apply(k, self.group)
v = first_alltoall.apply(v, self.group)
dropout_p, softmax_scale = 0, q.shape[-1] ** (-0.5)
out = flash_attn_func(q, k, v, dropout_p, softmax_scale)
if P > 1: # (H/P, B, T, E) -> (H, B, T/P, E)
out = second_alltoall.apply(out, self.group)
out = out.permute(1, 2, 0, 3) # (H, B, T/P, E) -> (B, T/P, H, E)
out = out.reshape(B, T // P, -1) # (B, T/P, H, E) -> (B, T/P, H*E)
out = self.proj(out) # (B, T/P, H*E) -> (B, T/P, E)
out = self.dropout(out)
return out
And that is it. It’s pretty simple, but if you are looking for the full implementation, check gptlite_ulisses_sequence_parallelism.py.
Also, as an important note, there are other similar approaches to handle this problem, such as ColAI-SP and Megatron-SP, however the big advantage of DeepSpeed Ulysses parallelism is that it requires less communication than the alternatives. However, the only downsides are that the maximum parallelism is dictated by the number of attention heads (typically 8), and that the all-two-all requires blocking collective communication that may incur a heavy overhead on networks of processes wil slow communicaion. That’s where Ring Attention comes into play.
Ring Attention with Blockwise Transformers
Ring attention was presented in the paper Ring Attention with Blockwise Transformers for Near-Infinite Context based on Blockwise Parallel Transformer for Large Context Models. It performs a per-block computation of the attention matrix, that allows one to compute the attention \(softmax \left(QK^T \right)\) without having access to the full inputs \(Q\), \(K\) and \(V\). It can be viewed as a distributed version of Flash Attention. The whole rationale was presented in the paper Self-attention Does Not Need \(O(n^2)\) Memory. In practice, given a query \(q\), key \(k\) and value \(v\) tensor, the output of an attention head can be reduced to:
\[\begin{align*} Attention(Q, K, V) & = softmax \left(QK^T \right) V \\ & = softmax \left( \sum_i dot(q, k_i) \right) v_i & \text{(expanding dot-product on k)}\\ & = softmax \left( \sum_i s_i \right) v_i & \text{ (for simplicity, take } s_i = dot(q, k_i) \text{)} \\ & = \sum_i softmax \left( s_i \right) v_i & \text{(sofmax of sum = sum of softmax)}\\ & = \sum_i \left( \frac{\exp \left( s_i \right)}{ \sum_j \exp\left( s_j \right)} \right) v_i & \text{(definition of softmax)}\\ & = \frac{ \sum_i \exp\left( s_i \right) v_i }{ \sum_j \exp\left( s_j \right) }. \end{align*}\]This trick exposes a property that the output is a fraction, whose upper and lower terms can be computed independently as a sum of terms. Therefure, we do not need to load the full \(v\) and \(k\) tensors or store the full attention matrix \(QK^T\) in memory. Instead:
- in the forward pass, we iterate over the \(i\)-th element of the tensors \(v\) and \(k\), and perform the accumulations \(v^{\star} \leftarrow v^{\star} + \exp(s_i) v_i\) for the top term in the fraction, and \(s^{\star} \leftarrow s^{\star} + \exp(s_i)\) for the bottom term;
- after processing all keys and values, we divide \(\frac{v^{\star}}{s^{\star}}\) to get the final attention output value;
- in the backward pass we compute the gradients iteratively for the same blocks, therefore not needing to store the whole attention matrix from the forward pass.
Improving numerical stability
The previous formulation is not numerically stable using floating point arithmetic because the softmax exponents can lead to very large numbers. The solution, quoting section 3 of the original paper, is to implement softmax by subtracting the maximum score from all scores. This does not change the result of the softmax, but avoids this numerical problem. This is called the safe softmax trick and is well explained in this post. The safe softmax formulation is:
\[safe\_softmax(s_i) = \frac{\exp (s_i)}{ \sum_j \exp( s_j )} \cdot \frac{\exp (-s_{max})}{\exp (-s_{max})} = \frac{\exp (s_i - s_{max})}{ \sum_j \exp( s_j - s_{max})}\]The issue is on how to compute the max value, when the computation is done in blocks. This is done by keeping the max value of all blocks seen so far by the iterative loop over blocks . Then, if the current maximum at block \(j\) is \(m_j\) and the previous maximum value until then was \(m_{j-1}\), then the accumulators are updated as:
\[\begin{align*} v^{\star} \leftarrow & v^{\star} \cdot \exp ( m_{i-1} - m_{i}) + \exp \left( s_i- m_{i} \right) \, v_i \\ s^{\star} \leftarrow & s^{\star} \cdot \exp( m_{j-1} - m_{j} ) + \exp \left( s_j- m_{j} \right) \end{align*}\]Finally, in practice, we dont compute \(v^{\star}\) and \(s^{\star}\) directly, but apply a small variation of the previous formulation where we accumulate log-values of the accumulators and the LogSumExp of values instead of \(v^{\star}\) and \(s^{\star}\) (described here ), due to the LSE property:
\[LSE (x_{1},\dots ,x_{n})=\log \left(\exp(x_{1})+\cdots +\exp(x_{n})\right)\]Distributed Algorithm
Now that we know how to compute the attention output per block, we can parallelize the computation of the attention by delegating a sub-block to each processor. We start with sequence parallelism of the tensors \(q\), \(k\) and \(v\) across \(P\) processes, ie each process hold a non-overlapping timeframe (block) of the \(q\), \(k\) and \(v\) tensors. Just like Ulysses, this allows for direct \(P\)-order parallelism on the Feed-forward network, but not on the MultiHead attention. Thus, the MHA algorithm is as follow. During the computation of the MHA, sub-blocks of the \(q\) and \(v\) tensors will be rotated among all \(P\) processes in a ring fashion, iteratively: at each communication step (out of \(P\) steps), each process sends its block of keys and values to the next process, and receives the keys and values of the previous processor in the ring. After \(P\) communication steps, all processes will have received the full \(k\) and \(v\) tensors, in chunks, and will have its original tensors returned to its local memory. This pattern can be illustrated as:
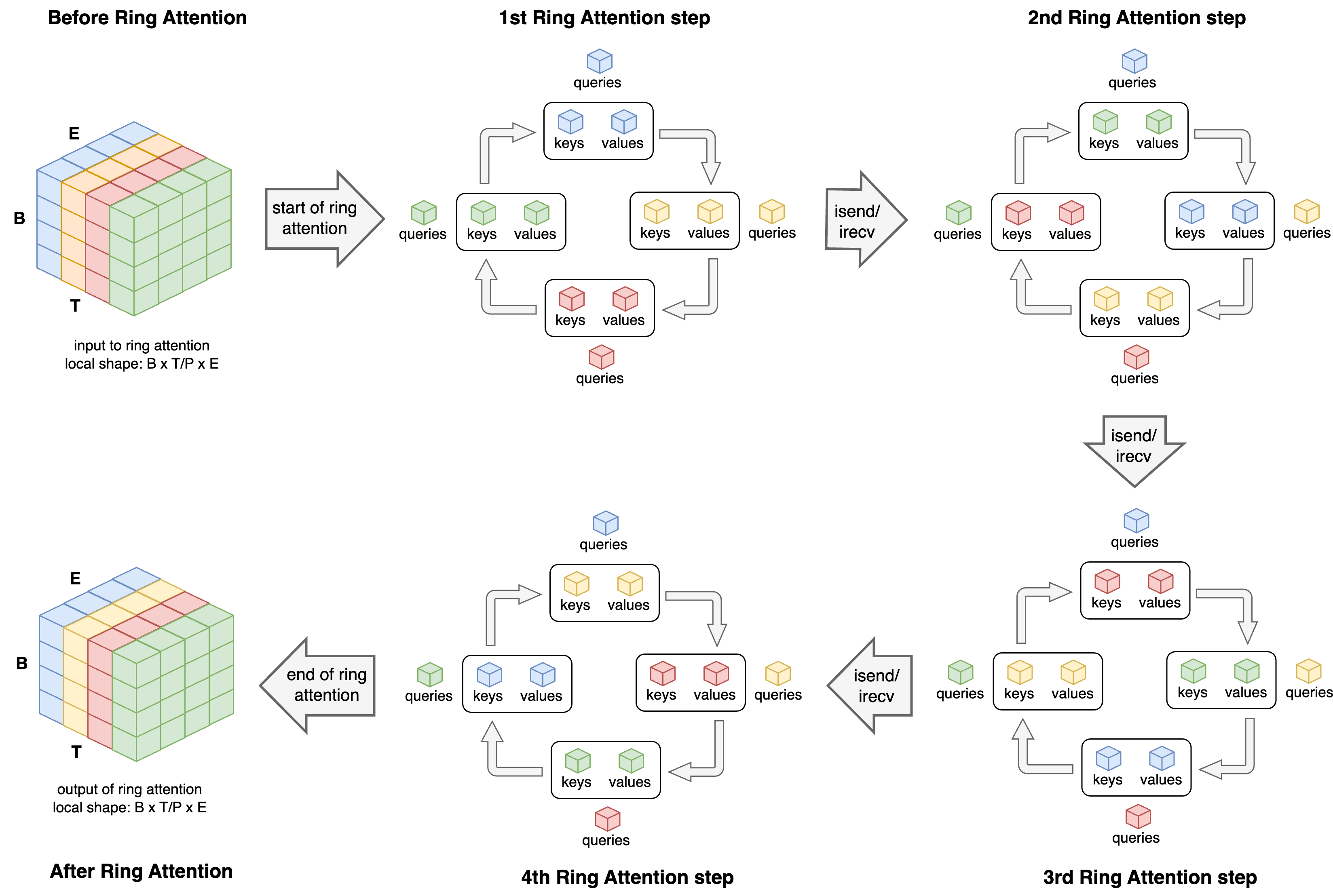
Overview of the Ring Attention algorithm. Before Ring Attention: the initial view of the input tensor, distributed across 4 (color-coded) gpus, split by the time (T) dimension. 1st Ring Attention Step: the first step of the ring attention. Each process holds its part of the Query, Value and Key tensors. Each process computes the block attention for those tensors. Asynchronously, processes perform an async send of the Key and Value tensors to the next process in the communication ring (clockwise). 2nd, 3rd, and 4th Ring Attention steps: Each process receives the previous process Key and Value blocks and are now able to compute attention outpout for its original Query tensor and the received Key and Value tensors. After Ring Attention: the Multi-head attention output is already time-split across processes, similarly to the initial data format.
From a process standpoint, after all the ring steps, each process was presented with their own timeframe of \(q\) and the full \(k\) and \(v\) tensors. As an example, for the third (red) process above, we’d have the following data presented:
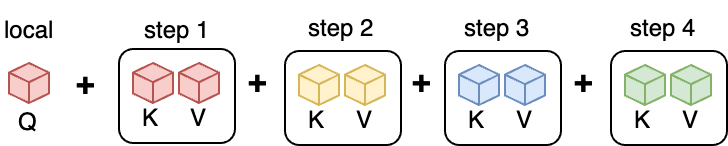
Implementation
The forward pass will perform \(P\) ring communication steps, and on each step, it will compute for the current \(K\), \(Q\) \(V\) block, the attention output and the LogSumExp of each row of the matrix \(QK^T\) (variables block_out and block_lse), in order to do the accumulation:
import flash_attn.flash_attn_interface as fa # flash attention
class RingAttention(torch.autograd.Function):
def forward( ctx, q, k, v, group ):
P = group.size()
q, k, v = q.contiguous(), k.contiguous(), v.contiguous() # (B, T/P, H, E)
out = lse = None # accumulators
recv_k, recv_v = torch.empty_like(k), torch.empty_like(v) # recv buffers
for step in range(P): # do P ring steps
# send already the K and V for next step, asynchronously
reqs_k_v = isend_k_and_v(k, v, recv_k, recv_v, group)
# compute attention output and softmax lse for current block
dropout_p, softmax_scale = 0, q.shape[-1] ** (-0.5)
kwargs = dict(causal=False, window_size=(-1, -1), softcap=0.0, alibi_slopes=None, return_softmax=False)
block_out, _, _, _, _, block_lse, _, _ = fa._flash_attn_forward(q,k,v, dropout_p, softmax_scale, **kwargs)
# update out and lse
out, lse = accumulate_out_and_lse(out, lse, block_out, block_lse)
# wait for new K and V before starting the next iteration
[ req.wait() for req in reqs_k_v]
k, v = recv_k, recv_v
ctx.group = group # save for backward
out = out.to(dtype=q.dtype)
ctx.save_for_backward(q, k, v, out, lse)
return out
where isend_k_and_v(k, v, recv_k, recv_v, group) is the function that sends the tensors k and v to the next neighbour asynchronously, receives the previous neighbour’s k and v into recv_k and recv_v asynchronously, and returns the send/receive communication futures that have to waited as req.wait() .
The backward pass will take as input the gradient of the loss with respect to the output (\(\nabla_{out} Loss\) or dout in the code below), and return the gradients of the loss with respect to the parameters of the functions (gradients \(\nabla_{q} Loss\), \(\nabla_{k} Loss\), \(\nabla_{v} Loss\), or dq, dk, dv). Something similar to:
def backward(ctx, dout, *args):
P = ctx.group.size()
q, k, v, out, softmax_lse = ctx.saved_tensors
softmax_lse = softmax_lse.squeeze(dim=-1).transpose(1, 2)
block_dq, block_dk, block_dv = torch.empty_like(q), torch.empty_like(k), torch.empty_like(v) # output buffers
dq, dk, dv = torch.zeros_like(q), torch.zeros_like(k), torch.zeros_like(v) # accumulators of gradients
recv_k, recv_v = torch.empty_like(k), torch.empty_like(v) # recv buffers for K and V
recv_dk, recv_dv = torch.empty_like(dk), torch.empty_like(dv) # recv buffers for dK and dV
for step in range(P):
# send already the K and V for next step, asynchronously
reqs_k_v = isend_k_and_v(k, v, recv_k, recv_v, group)
# compute the gradients for the current block K, V and Q
dropout_p, softmax_scale = 0, q.shape[-1] ** (-0.5)
kwargs = dict(causal=False, window_size=(-1, -1), softcap=0.0, alibi_slopes=None, deterministic=False, rng_state=None)
fa._flash_attn_backward(dout, q, k, k, out, softmax_lse, block_dq, block_dk, block_dv, dropout_p, softmax_scale, **kwargs)
if step > 0:
# wait for dK and dV from the previous steps, they're the dK and dV accumulators
[ req.wait() for req in reqs_dk_dv]
dk, dv = recv_dk, recv_dv
dq += block_dq
dk += block_dk
dv += block_dv
reqs_dk_dv = isend_k_and_v(dk, dv, recv_dk, recv_dv, group)
# wait for new K and V before starting the next iteration
[ req.wait() for req in reqs_k_v]
k, v = recv_k, recv_v
# before returning, wait for the last dK and dV, that relate to this process block
[ req.wait() for req in reqs_dk_dv]
dk, dv = recv_dk, recv_dv
return dq, dk, dv, None
A small nuance in the backward pass is that the gradients of a given block will refer to the current \(K\) and \(V\) which is being rotated around processes. Therefore, the gradients dv and dk will also be accumulated by being rotated alongside their k and v blocks.
Finally, the forward pass of the multi head attention is straighforward and will simply call to ring attention’s implementation instead of the regular attention:
class MultiHeadAttention(nn.Module):
def forward(self, x):
P, B, T, = self.group.size(), x.shape[0], x.shape[1] * self.group.size()
# take Q, K and V, and collect all head embeddings: (B, T/P, E) -> (H, B, T/P, E)
q = torch.stack([q(x) for q in self.queries], dim=0)
k = torch.stack([k(x) for k in self.keys], dim=0)
v = torch.stack([v(x) for v in self.values], dim=0)
if P == 1:
out = fa.flash_attn_func(q, k, v)
else:
out = RingAttention.apply( q, k, v, self.group)
out = out.permute(1, 2, 0, 3) # (H, B, T/P, E) -> (B, T/P, H, E)
out = out.reshape(B, T // P, -1) # (B, T/P, H, E) -> (B, T/P, H*E)
out = self.proj(out) # (B, T/P, H*E) -> (B, T/P, E)
out = self.dropout(out)
return out
And we are done. Now, as you can see, the big disavantadge in ring attention is the number of steps communication being identical to the number of processes. This may be a limiting factor on large compute networks where dividing sequences in such a granular fashion may lead to a small workload assigned to each process. This eventually will make computation very small and unable to mitigate completely the communication, leading to a poor executing efficiency.
Training with sequence- and multi-dimensional parallelism
Pytorch does not have the notion of partial sentences, thus all samples being processed in parallel are assumed to be full-length samples on a data-parallel execution. To overcome this, when you run sequence parallelism of order S, you should perform S gradient accumulation steps with the corresponding gradients scaling, so that it processes the correct batch size per step, and gradients are properly averaged.
Moreover, when you perform multi-dimensional parallelism (e.g. at data- and sequence levels), you need to define the process groups for the data parallelel processes (the ones that load different samples) and the sequence parallel processes (the ones that load different chunks of the same sample and perform sequence parallelism for that sample). You can do this with Pytorch’s DeviceMesh mesh or create your own process groups manually. For the sake of illustration, if you’d implement a \(2 \times 2\) Data- and Ulysses sequence parallelism on 4 GPUs, this would be the memory layout before and during the Multi-Head Attention:
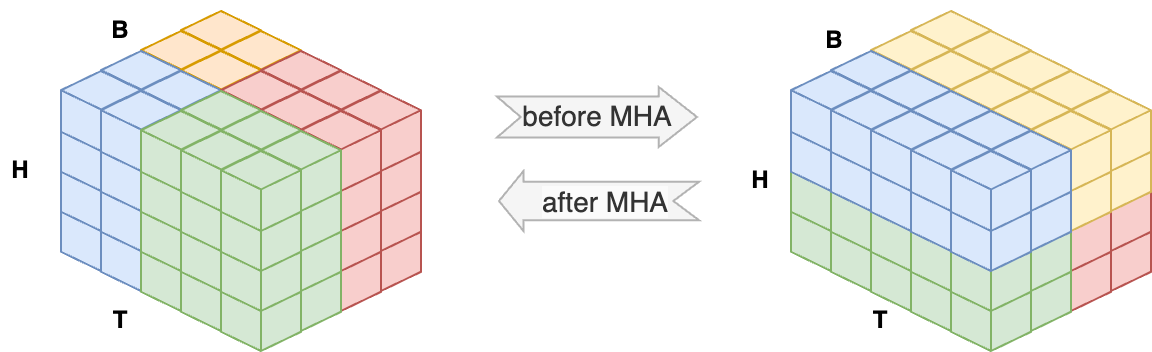
Activations allocation on a 4-GPU parallelism with 2-GPU data parallelism and 2-GPU Ulysses sequence parallelism. Left: blue and green processes belong to the same sequence-parallel group and share one sample; red and yellow processes form the other sequence-parallel group and share the other sample. Right: the first all-to-all in Ulysses parallelism converts a token-level distributed storage into a head-level distributed storage. All four processes can compute the attention for full sentences.
Code and final remarks
This code has been added to the GPT-lite-distributed repo, if you want to try it. When you run it, keep in mind that deterministic behaviour on sequence parallelism across networks of different proces count is difficult due to random number generators producing different values on each node - e.g. during model initialization and dropout.
Finally, both two methods have some drawbacks: Ulysses yields a reduced number of communication steps but low parallelism, while Ring Attention will give high parallelism with communication steps. The ideal solution would then be a hybrid of Ulysses parallelism and Ring attention. This has already been presented in USP: A Unified Sequence Parallelism Approach for Long Context Generative AI. If you’re looking for finer-granularity in sequence parallelism, check the head-parallel and context-parallel implementation of 2D-attention in LoongTrain: Efficient Training of Long-Sequence LLMs with Head-Context Parallelism.