Learning from sequences: Encoder-Decoder, Transformers and BERT
In this post we will look into alternative methods for ML training on sequential data, with an emphasis on efficiency and parallelism.
Encoder-Decoder and Sequence-to-Sequence
The Encoder-Decoder (original paper Sequence to Sequence Learning with Neural Networks (Google, arXiv)) is an AutoEncoder model that learns an encoding and a decoding task applied to two sequences, i.e. it trains for a sequence-to-sequence task such as the translation of a sentence from a given language to a target language. The learning mechanism is a two-phase recursive algorithm, for the encoder and decoder respectively, where each phase is a sequence of iterations over a recursive neural network.
The structure of its Recursive Deep Neural Network (RNN) is as follows:
- Words are past as part of the input, represented by an embedding of dimensionality \(d\);
- The neurons used in the model are not stateless (e.g. like in a regular neuron with an activation function), but have an internal state. Two common examples are Long Short-Term Memory neurons (LSTM) and Gated Recurrent Units (GRU). The set of state variables of the neurons on a single are the layer’s hidden state. In this example, as in most application, we’ll focus on GRU as it includes a single state variable on each neuron (versus two on the LSTM counterpart), making it faster to train;
- The network has three fully connected layers:
- an output layer of size \(h\), whose output value is the embedding of the predicted/groundtruth word;
- a single hiddle layer of size \(d\), refering to the hidden space of the current iteration;
- an input layer of length \(h+d\) (when utilizing GRU neurons) or \(2h+d\) (LSTM), referring to the concatenation of the embedding of the previous iteration’s hidden space (we’ll cover this next), and the embeding of the current word being input. On the first iteration, the input is initialized randomly or with a zero vector;
This structure is easily represented by the following picture:
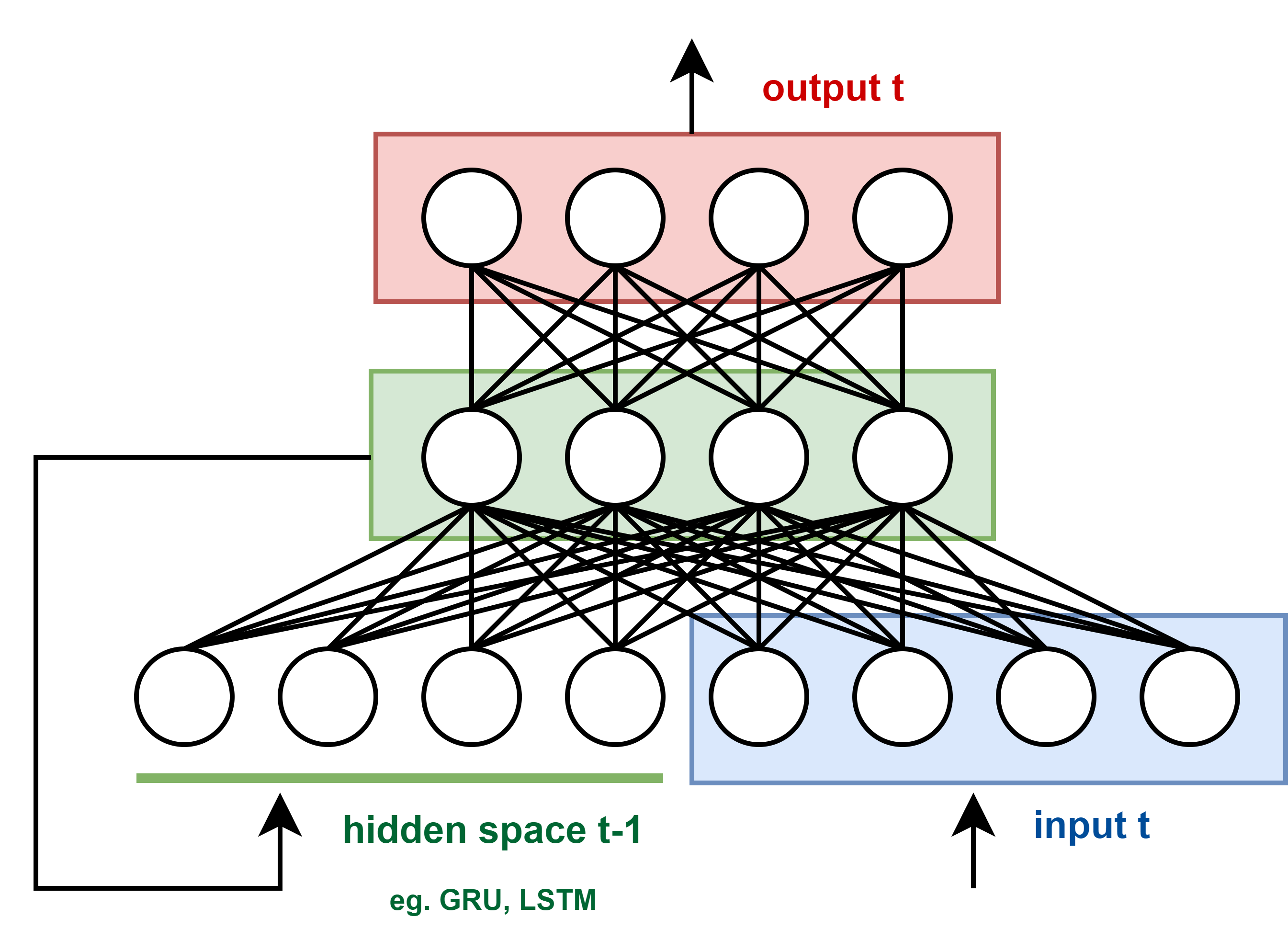
The recursive deep neural network trained on each step of the encoder-decoder architecture. The blue area represent input neurons. The green area represents a single hidden layer formed by the states of the GRU/LSTM neurons of the RNN. The red area represents the model output. The concatenation of the hidden layer of the previous iteration and the current iteration’s input are used as model input.
The training follows with an encoding and decoding phase:
- During the encoding, the RNN processes all the words on the input sequence iteratively, and reutilizes (concatenates) the hidden state of an iteration as input of the next one. The output of the RNN is discarded, as we are simply training the hidden states. When all words have been processed, the hidden state of the RNN is past as input to the first iteration of the decoder;
- The decoder takes on its first step the last encoder’s hidden space and concatenates it with the Beginning of Sentence (BOS) flag (user-defined, usually a vector with only zeros or ones). The output is the first predicted word in the target language. All following steps are simillar: the output and hidden state of a single step is past as input to the next one, and the model can then be trained based on the loss on the output (translated word). The last iteration’s output is the flag End of String (EOS), built similarly to BOS. Training of the RNN iterations happens at every iteration, as in a normal Deep Neural Network.
This algorithm can be illustrated as:

The workflow of an encoder-decoder architecture training by learning the translation of the english sentence “Hello World.” to the Frence sentence “Bonjour le monde.”.
Two relevant remarks about the Encoder-Decoder architecture:
- Once the network is trained, the translation of a new sentence is executed by running encoder iterations until the flag EOS is output;
- An improvement based on the concept of Attention Mechanism delivers improved results by utilising the hidden space of every encoder iteration (not just the last) on the decoding steps, in order to increase the model capatiblities (original paper: Bahdanau et al. Neural Machine Translation by Jointly Learning to Align and Translate);
For the sake of brevity, we will ommit these details and refer you to the Pytorch turorial “NLP from scratch: translation with a sequence to sequence network and attention” if you are curious about the implementation details of regular and attention-based encoder-decoders. Let’s go back to the main subject of this post and the topic of computational complexity.
Parallelism, scaling and acceleration of such sequence-to-sequence models is an issue. There are four main reasons that explain this:
- encoding/decoding is a recursive algorithm, and we can’t parallelize recursive iterations, as each iteration depends on the hidden state of the previous one;
- the DNN underlying the RNN architecture has only a single layer, therefore model parallelism like pipelining (covered in our previous post) won’t provide any gains;
- the hidden layer is composed of \(h\) neurons, and \(h\) is usually a value small enought to allow for acceleration at the layer level (e.g. the model parallelism showned in the our previous post;
- input and output sequences have different lengths, and each batch needs to be a set of input and output sentences of similar lenghts, which makes the batches small and inefficient to parallelize. In practice, some batching is possible by grouping sentences first by length of the encoder inputs, and for each encoder, group by length of decoder inputs. This is however very inneficient as we require an extremmly high number of sentences so that all groups of encoder/decoder pairs are large enough to fully utilize the compute resources at every training batch. Not impossible, but very unlikely.
Transformer
Note: the original Transformer paper is also detailed in the section publications bookmark.
In 2017 the staff at Google introducted the Transformer (original paper Attention is all you need (2017, Google, Arxiv)), overcoming many of the previous issues, while demonstrating better results. The transformer architecture is the following:
![]()
The transformer architecture. Grey regions represent the Encoder (left) and Decoder (right) architectures. Source: Attention is all you need (2017, Google, Arxiv)
The left and right hand side components refer to the encoder and decoder, specifically. We will describe these components in the next sections, and ommit the implementation details to focus on computational complexity. If you’re curious about its implementation, have a look at The Annotated Transformer.
Word and Positional Embeddig
The first unit of importance in the transformer is the embedding unit combined with the positional encoding (red boxes and circles in the previous picture). The transformer model has no recurrence or convolution, so we need a positional encoder to learn the context of a sequence based on the order of its words. Without it, it can only learn from the input as a set of values, not as a sequence, and inputs with swapped tokens would yield the same output. According to the paper, the embedding position \(d\) of a given word in the position \(pos\) of a sentence is:
- \(PE_{(pos,2i)} = sin\left(\frac{pos}{10000^{2i/d}}\right)\) for an even position \(d\) and
- \(PE_{(pos,2i+1)} = cos\left(\frac{pos}{10000^{2i/d}}\right)\) otherwise.
In practice, the embedding is given by the \(sine\) and \(cosine\) waves with a different frequency and offset for each dimension. As an example, for a word with positioning \(pos\) (x axis), then the values at dimensions \(4\), \(5\), \(6\) and \(7\) is:
![]()
The output of the positional encoding in the transformer architecture, for dimensions 4 to 7 of the embedding array, for a word with a sentence-positioning related to the x axis. Source: The Annotated Transformer
Attention Mechanism
The main component of the transformer is the attention mechanism, that determines how the words in input and output sentences interact. In brief, it’s the component that learns the relationship between words in such a way that it learns the relevant bits of information on each context (thus the naming Attention mechanism). The transformer architecture includes not one, but several of these mechanisms, executed in parallel, to allow the model to learn multiple relevant aspects of the input. This Multi-head Attention Mechanism solves for \(n\) heads, What part of the input should I focus on?
Let’s look at a single head of attention mechanism for now. Take the sentence of length \(N\) words, how is each word related to every other word on that sentence? The output of a single attention mechanism is then the \(N \times N\) matrix storing these inter-word importance metric. Here’s an example:
![]()
The attention mechanism output. For the sentence of length \(N=4\) “The big red dog” the output at every row of the attention matrix is the normalized relevance metric of that word to every other word in the sentence. Source: unknown.
How does this mechanism work? According to the paper, each attention head is formulated as:
\[Attention(K, V, Q) = A \, V = softmax\left( \frac{QK^T}{\sqrt{D^{QK}}} \right) V\]Where:
- \(Q\) is a tensor of queries of size \(N^Q×D^{QK}\)
- \(K\) is a tensor of keys of size \(N^{KV}×D^{QK}\), and
- \(V\) is a tensor values of size \(N^{KV}×D^V\), thus
- \(Attention(K,V,Q)\) is of dimension \(N^Q×D^V\).
The tensor \(A\) is the attention score where \(A_{q,k}\) is computed for every query index \(q\) and every key index \(k\), as the argmax of the softmax (softargmax), of the dot products between the query \(Q_q\) and the keys:
\[A_{q,k} = \frac{ \exp \left( \frac{1}{\sqrt{D^{QK}} } Q^{\intercal}_q K_k \right) }{ \sum_l \exp \left( \frac{1}{\sqrt{D^{QK}}} Q^{\intercal}_q K_l \right) }\]The term \(\frac{1}{\sqrt{D^{QK}}}\) helps keeping the range of values roughly unchanged even for large \(D^{QK}\). For each query, the final value is computed for as a weighted sum of the input values by the attention scores as: \(Y_q = \sum_k A_{q,k} \, V_k\).
![]()
The attention operator can be interpreted as matching every query \(Q_q\) with all the keys \(K_1, ..., K_{N^{KV}}\) to get normalized attention scores \(A_{q,1},...,A_{q,N^{KV}}\) (left), and then averaging the values \(V_1,...,V_{N^{KV}}\) with these scores to compute the resulting \(Y_q\) (right). Source: the little book of deep learning.
Notice that in the transformer diagram, each attention module has three inputs (arrows) referring to these three variables. The attention mechanism at the start of each encoder and decoder is retrieving keys, values and queries from its own input, learning the context of the source and target languages, respectively. However, in one occurence of the attention mechanism, the keys and values are provided by the encoder, and the query by the decoder, relating to the module that is trained for the translation at hand.
Finally, the multi-head attention mechanims combines all attention mechanism modules, and is defined as:
\[MHA(K, V, Q) = [head_0,.., head_n]W^{MHA} \,\text{ and }\, head_i = Attention(KW^K_i, VW^V_i, QW^Q_i)\]I.e. it’s a concatenation of all attention heads, and the parameters learnt are the weights of the keys (\(W^K_i\)), values (\(W^V_i\)) and query (\(W^Q_i\)) space of each head \(i\), and a final transformation of the multi-head concatenation \(W^{MHA}\). In terms of computational complexity, the attention mechanism on the encoder is trained on the complete input sequence at once (as illustrated in the “the big red dog” example), instead of looping through all words in the input sequence. Therefore, the attention mechanism replaces the recursive (RNN) iterations on an encoder, by a set of matrix-vector multiplications.
The Masked Multi-head Attention component on the decoder is similar to the regular MHA, but replaces the top diagonal of the attention mechanism matrix by zeros, to hide next word from the model. Decoding is performed with a word of the output sequence of a time, with previously seen words added to the attention array, and the following words set to zero. Applied to the previous example, the four iterations are:
![]()
Input of the masked attention mechanism on the decoder for the sentence “Le gros chien rouge”. The algorithm performs four iterations, one per word. Attention is computed for every word iterated. The mask component of the attention mechanism refers to replacing (in the attention matrix) the position of unseen words by zero. Source: unknown.
Other components
The other components on the transformer are not unique, and have been used previously in other machine learning models:
- The Feed Forward is a regressor (single hidden-layer DNN) that transforms the attention vectors into a form that is valid as input to the decoder or to the next computation phase;
- The Linear transformation component on the decoder expands the space into an array of size equals to the target vocabulary (French in the example);
- The Softmax operation transforms the output of the previous layer into a probability distribution. The word with the highest probability is picked as output;
Computational Complexity
Besides the great reduction in the number of iterations on the encoder size, the authors compare the computational complexity of four comparative models:
![]()
Comparative table of computational complexity of four different learning models. Key: \(n\): sequence length, \(d\): representation dim., \(k\): kernel size; \(r\): size of neighbourhood. Source: Attention is all you need (2017, Google, Arxiv)
For the RNN used in previous Sequence-to-Sequence mechanism, the number of operations performed is in the order of \(d^2\) multiplications (multiplication of weights in a fully-connected layer of a DNN) for each of the \(n\) words in the sentence, therefore \(O(n^2 d)\). On the self-attention mechanism that we discussed in the Transformer, we have several operations of the attention matrix \(n^2\) and the key and query vectors of embedding size \(d\), therefore yielding a complexity of \(O(n d^2)\).
The claim is that the \(O(n^2 d)\) is better than \(O(n d^2)\). This sound illogical in most Machine Learning problems as typically the input size is way larger than the dimensionality of the embedding. However, remember that \(n\) here is the number of words in a sentence (in the order of \(n \approx 70\)) and \(d\) is the size of the embedding (\(d \approx 2000\)).
To summarize, the encoder-decoder architecture of the transformer allows a faster non-recursive training of input sequences, and a faster training of output sentences, making it much more efficient than the sequence-to-sequence approaches discussed initially.
BERT: Bidirectional Encoder Representation from Transformers
Note: the original BERT paper is also detailed in the section publications bookmark.
Attending to the previous topic, the main rationale of the Transformer’s Encoder-Decoder is that:
- The encoder learns the context of the input language (English in the previous example);
- The decoder learns the task of the input-to-output languages (the English-to-French translation);
So, the encoder is efficiently trained and learns a context. So the main question is “Can we use only the Encoder’s context and learn complex tasks?”. This led to the introduction of the BERT model (original paper BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Google AI). BERT is a stack of Transformer encoders that Learns language contexts and performs interpretation tasks.

The BERT model, as a stack of Transformer encoders.
The training is performed in two phases. A pre-training phase learns the contexts of the language. And a fine-tuning phase adapts the trained model to the task being solved. Let’s start with the pre-training.
Pre-training
The pre-training phase is based on the simultaneous resolution of two self-supervised prediction tasks:
- Masked language model: given a sentence with works replaced with a flag (or masked), train it against the same sentence with those words in place;
- Next sentence prediction: Given two sentences, train the model to guess if the second sentence follows from the first or not;
Example of two training examples:
Input = [CLS] the man went to [MASK] store [SEP] He bought a gallon [MASK] milk [SEP]
Output = [IsNext] the man went to the store [SEP] He bought a gallon of milk [SEP]
Input = [CLS] the man [MASK] to the store [SEP] penguins [MASK] to jump [SEP]
Output = [NotNext] the man went to the store [SEP] penguins like to jump [SEP]
Note that the Yes/No flag related to the second task is past as the first embedded word in the output. The layout of the input data is:
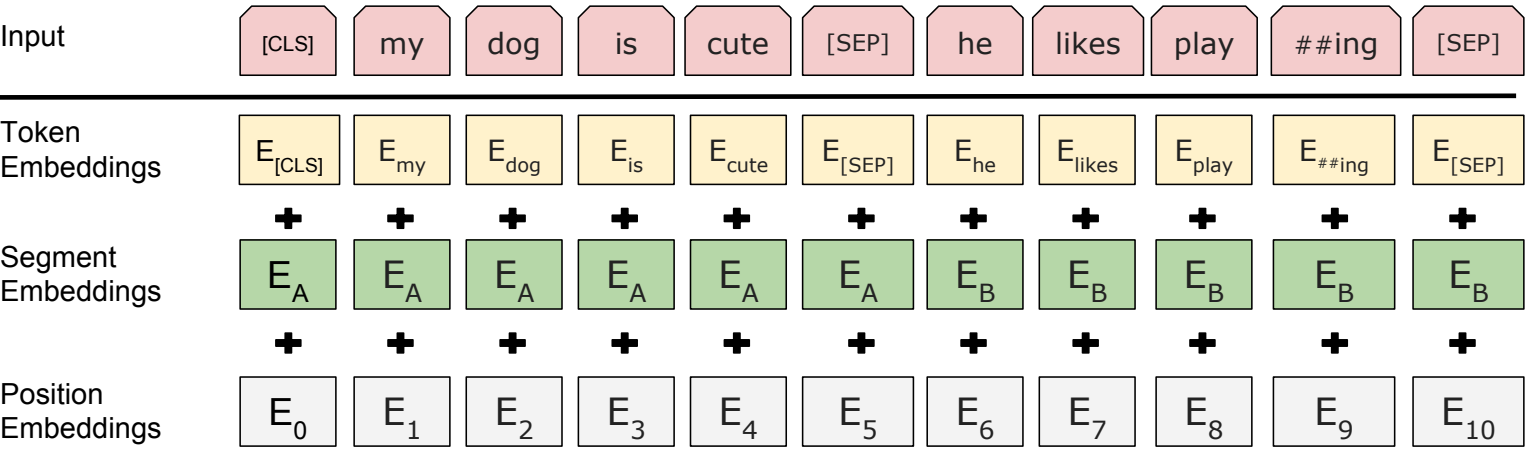
The input of the BERT model. Position Emdebbings are similar to the transformer model, discussed above. Segment embeddings flag each word as part of the first or second sentence. Token embedding are the text-embeddings of the input data. The datapoint being input to the model is the concatenation of these three embeddings. Source: Attention is all you need (2017, Google, Arxiv)
As a side note, the authors trained this model on BooksCorpus (800M words) and English Wikipedia (2,500M words), using 24 BERT layers, batches of 256 sentences with 512 tokens each.
Fine-tuning
The fine-tuning phase adds an extra layer to the pre-trained BERT model, in order to train the model to the task at hand. This approach has been applied previously in other models, particularly on Convolutional Neural Nets, where the first layers are pre-trained and learnt edges and lines, and the remaining layers are added later and used on the training of the object-specific detection.
In the original paper, the authors demonstrated this model successfully being applied to four families of tasks:
- Sentence Pair Classification Tasks: classification of context from pairs of sentences. Examples: do sentences agree/disagree, does the second sentence follow from the previous one, do they describe a simillar context, etc. Similarly to the pre-training phase of the BERT models, the label is past as the first embedded symbol of the output;
- Single Sentence Classification Tasks: similar to the previous, but applied to a single sentence. Used for learning contexts like finding hateful speech, etc.;
- Question Answering Tasks: allows one to pass as input the concatenation of the question and a paragraph where the answer to the question is available. The output of the model is the input with the embeddings representing the start and end word of the answer replaced by a marker. As an example:
- input: “[CLS] His name is John. John is a Swiss carpenter and he is 23 years old [SEP] How old is John”;
- output: “[CLS] His name is John. John is a Swiss carpenter and ###he is 23 years old### [SEP] How old is John”;
- Single Sentence Tagging tasks: retrieves the classes of individual words e.g. Name, Location, Job, etc, by replacing each relevant word with its class id. As an example:
- input: “[CLS] His name is John. John is a Swiss carpenter and he is 23 years old”;
- output: “[CLS] His name is [NAME]. [NAME] is a [NATIONALITY] [OCCUPATION] and he is [AGE] years old”.
The input and output models of the fine-tuning of these tasks are illustrated in the following picture:
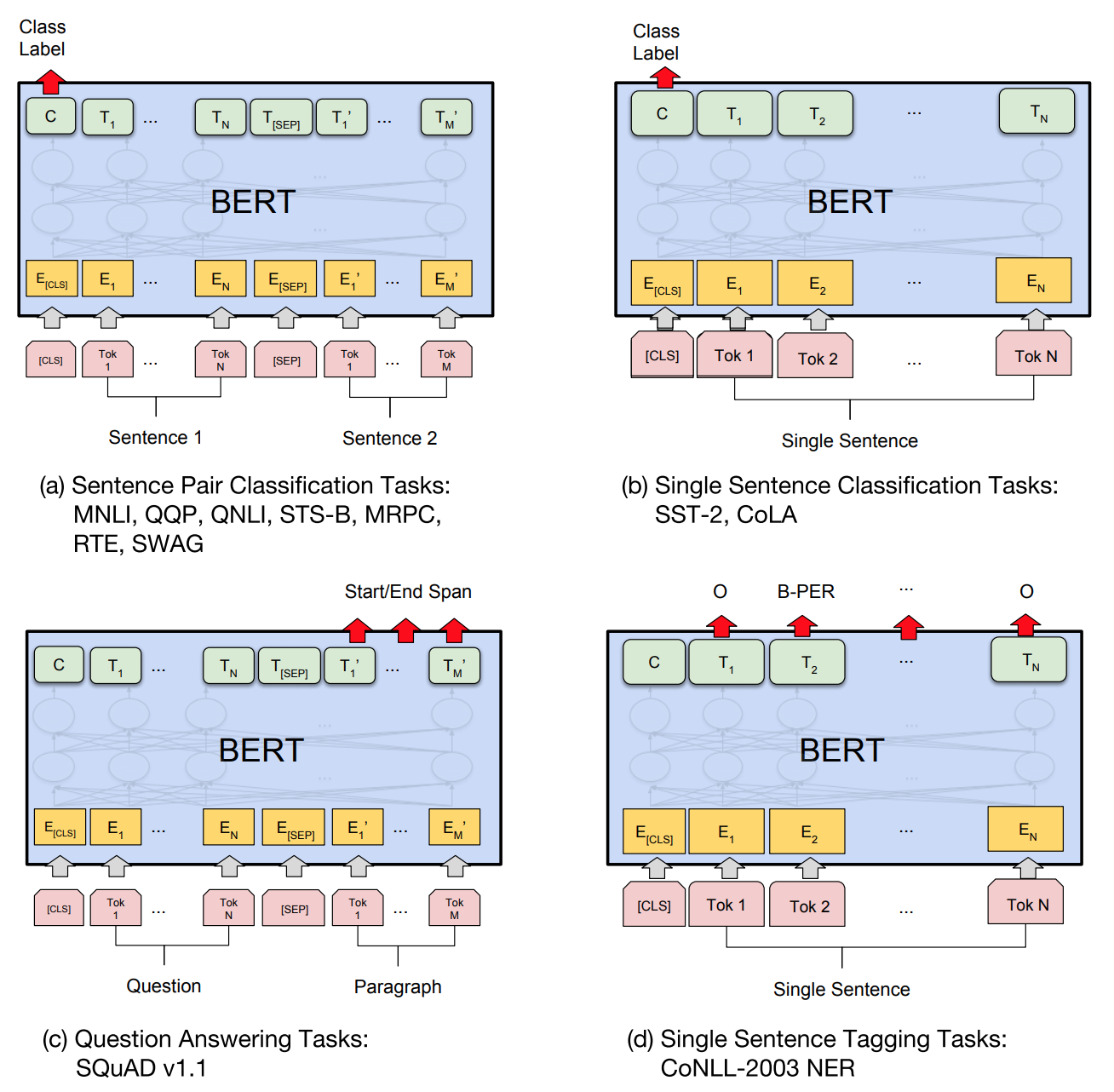
Input and output of the fine-tuning phase of a BERT network, applied to four different interpretation tasks. Source: Attention is all you need (2017, Google, Arxiv)
As a final note, information encoded by BERT is useful but, on its own, insufficient to perform a translation task. However, “BERT pre-training allows for a better initialization point for [an] Neural Machine Translation model” (source: Clichant et al.,On the use of BERT for Neural Machine Translation, arXiv).